Deep Learning is the branch of machine learning and AI that involves very deep (multiple layers of neural networks) networks processing humongous amounts of data to learn features, patterns and underlying relationships between the data. The large datasets need to be loaded on the memory on the machine and is a computationally expensive step. Data Loaders help load the huge chunks of data on the machine, either on the memory or the GPU in the most computationally optimized methods.
Introduction
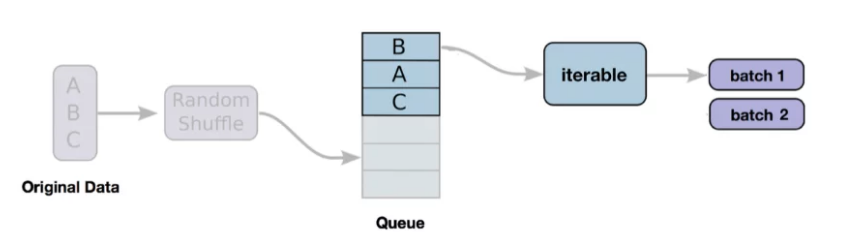
For small datasets, it is straightforward to load the complete data on the memory at once and run training on the device. Deep learning involves data in gigabytes and it is not feasible to load it on the memory directly. Pytorch, one of the famous libraries for DL has an in-built data loader that helps parallelize the process of data loading and also automates batching with shuffling and other plumbing tasks around data handling and augmentation.
Pytorch Data Loader
Pytorch’s DataLoader class is a part of the torch.utils.data package.
Its standard syntax is
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
where the parameters are
-
dataset- It is the compulsory object that holds the data. The dataset could either be map-style or iterable-style datasets. Each element of the map-style dataset is retrieved using the__get_item__()method implementation. Each element of the iterable-style dataset is fetched using the__iter__()protocol. This helps fetch data through a sequence stream instead of random reads for map datasets. batch_size- Number of samples per batchshuffle- If the data is to be shuffled or notsampler- Atorch.utils.data.Samplerclass object that defines the rules to extract the samples - either sequential or random or other rule. Shuffle and sampler should not be active simulatenously.num_workers- Number of sub-processes spawned during the data loading stepdrop_last- If the last batch is not the exact batch size, the last batch is dropped.
Dataloaders On Inbuilt Dataset
The torchvision package is a collection of pretrained models and datasets like ResNet50, ImageNet, VCG16 and more models and MNIST, CIFAR10 and other datasets.
Transforms supported by Pytorch are useful in manipulating the data. Primarily for CNN applications, the transform includes manipulations like resizing, data augmentation, normalization, random crops and more. Transformations are stacked sequentially and applied on an image. Some of them are applicable to Pytorch Tensor while some of them are performed before the Tensor conversion.
- Sample data manipulation
Define a transform to normalize the data
- Sample dataloader
Download and load the training data
Each next batch of the data can be accessed using the __iter__(). Iterating over the dataloader can also access the batches.
Dataloaders on Custom Dataset
While the in-built datasets available in torchvision have predefined madatory methods, the __len()__ and the __get_item__() functions for accessing the data. Any custom dataset definition is a derived class of the Pytorch Dataset and needs to have these methods defined for usage.
Note: - This code has been copied from somewhere I don’t recall of.
 FumbleBot - Intelligent Walking Desktop Robot
FumbleBot - Intelligent Walking Desktop Robot